总结热迁移失败的几种情况如下:
vm内存读写过于频繁
被热迁移的vm内存读写速度超过了内存同步的速度,让热迁移一直没办法完成内存在源节点和目的节点的同步。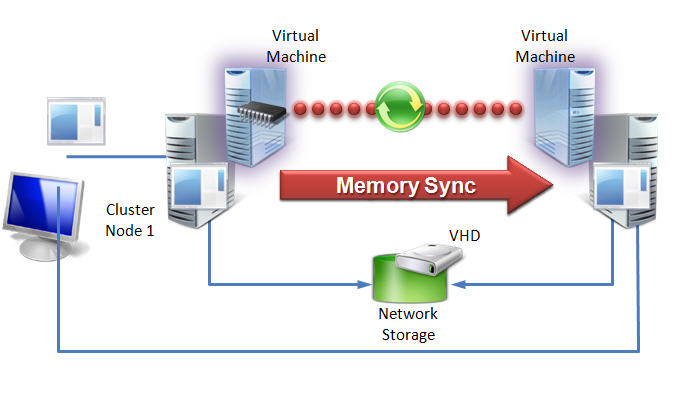
检查源节点和目的节点是否一致
- 在同一个subnet中
- 检查qemu版本号,内核版本号,cpu型号。
- At present, it is impossible to migrate an instance which has been configured to use CPU pinning.
- 热迁移依赖selinux模块。
Instance migration fails when using cpu-pinning from a numa-cell and flavor-property “hw:cpu_policy=dedicated”
We are having migration failures. The procedure was from section 3. “Migrate between hypervisors” (not a live migration).
The error message is as follows:
# nova migrate --poll $u
ERROR (BadRequest): No valid host was found. No valid host found for cold
migrate (HTTP 400) (Request-ID: req-592d59db-9185-4775-b5e2-940aa657a62c)
If however one VM is in shut off (on the destination host), then the other VM migration will succeed and the VM will come into service; for example, VM2 migrated from Host10 to Host03 while VM1 was shut off. However VM1 is no longer able to come into service as VM2 is using some of the same dedicated VCPUs.
Here is what you get when trying to power on the second VM that has VCPU collision with first one:
2016-02-16 17:30:49.860 58352 INFO nova.compute.resource_tracker
[req-9922b49b-c3e7-491f-b400-fa711b99eee1 - - - - -] Auditing locally available
compute resources for node mme06-host10
2016-02-16 17:30:50.806 58352 ERROR nova.openstack.common.periodic_task
[req-9922b49b-c3e7-491f-b400-fa711b99eee1 - - - - -] Error during
ComputeManager.update_available_resource: Cannot pin/unpin cpus [0, 1, 2, 3, 4,
5, 7, 8, 9, 20, 21, 22, 23, 24, 25, 27, 28, 29] from the following pinned set
[0, 1, 5, 8, 9, 20, 21, 25, 28, 29]It happens whenever the VCPU usage overlaps the usages already present in the possible destinations.
检查目的节点是否有足够的资源
- 目的节点是否有迁移vm所需的内存空间
- 若不是共享存储用block-migration,目的节点是否有vm所需要的disk空间
一个一个顺序迁移ok,多个同时迁移失败
还是按推荐的一个一个顺序热迁移。
* 0 : treated as unlimited.
* Any positive integer representing maximum concurrent builds.
"""),
# TODO(sfinucan): Add min parameter
cfg.IntOpt('max_concurrent_live_migrations',
default=1,
help="""
Maximum number of live migrations to run concurrently. This limit is enforced
to avoid outbound live migrations overwhelming the host/network and causing
failures. It is not recommended that you change this unless you are very sure
that doing so is safe and stable in your environment.
配置热迁移的带宽
Live migration generates excessive network traffic.
A live migration running at full speed can have a negative impact on the services that communicate over the same network; for example, the message queue. To set a lower maximum speed, use the following command:
# virsh migrate-setspeed domain speed_in_MBps
Alternatively, set the desired speed (again in MBps) beforehand. Example:
# openstack-config --set /etc/nova/nova.conf libvirt live_migration_bandwidth 50
用Gluster共享存储热迁移报vm的disk文件没有access权限错误,迁移失败
libvirt改变vm 镜像的owner,除非监测到在共享存储上。libvirt有NFS, GFS2 and SMB/CIFS,但是没有Gluster。所以Gluster环境,libvirt不能检测出是在共享存储的环境,disk文件在成功迁移之后会被赋给back to root:root,然而destination host会将disk文件赋给libvirt-qemu:kvm。
存在竞合关系,所以有可能会时不时的不能再次迁移。
解决方式:
stop your guests, then stop libvirt, and edit
/etc/libvirt/qemu.conf - this contains a commented out entry
‘dynamic_ownership=1’, which is the default. Change this to 0, and
remove the comment. Then do a chown to libvirt-qemu:kvm for all your
stopped images. Then you can start the service libvirt-bin again, and
bring up the guests. Repeat on the other half of your cluster, and test
a live migration.
举例
迁移前:
[root@compute ~]# ll /var/lib/nova/instances/4f4ed899-a485-401e-aae7-8029068a6be8/
total 4180
-rw-rw---- 1 nova kvm 17219 Jun 12 09:40 console.log
-rw-r--r-- 1 qemu kvm 4259840 Jun 12 09:41 disk
-rw-r--r-- 1 nova nova 79 Jun 12 09:40 disk.info
-rw-r--r-- 1 nova nova 1697 Jun 12 09:40 libvirt.xml
迁移后:
[root@compute ~]# ll /var/lib/nova/instances/4f4ed899-a485-401e-aae7-8029068a6be8/
total 4165
-rw-rw---- 1 root root 2221 Jun 12 10:03 console.log
-rw-r--r-- 1 root root 4259840 Jun 12 09:41 disk
-rw-r--r-- 1 nova nova 79 Jun 12 09:40 disk.info
-rw-r--r-- 1 nova nova 1697 Jun 12 10:03 libvirt.xml
做下面的设定即可
cat << EOF >> /etc/libvirt/qemu.conf
user="nova"
group="nova"
dynamic_ownership = 0
EOF
其他解决方式:
using libgfapi, giving libvirt direct access without
having to go through the filesystem. This is the preferred setup for
libvirt+gluster and should also result in better I/O performance.
Multipathing Requirements
When migrating an instance with multipathing configured, you need to ensure consistent multipath device naming between the source and destination nodes. The migration will fail if the instance cannot resolve multipath device names in the destination node.
You can ensure consistent multipath device naming by forcing both source and destination nodes to use device WWIDs. To do this, disable user-friendly names and restart multipathd by running these commands on both source and destination nodes:
# mpathconf --enable --user_friendly_names n
# systemctl restart multipathd
转载请注明来源,欢迎指出任何有错误或不够清晰的表达。可以邮件至 backendcloud@gmail.com

